Given a continuous stream of photos, we, as humans, would identify the start of an event if the new frame differs from the expectation we have generated. The proposed model is analogous to such intuitive framework of perceptual reasoning. It uses an encoder-decoder architecture to predict the visual context at time t given the images seen before, i.e. the past. A second visual context is predicted from the ensuing frames, i.e. the future. If the two predicted visual contexts differ greatly, CES will infer that the two sequences (past and future) correspond to different events, and will consider the frame at time t as a candidate event boundary.
Predicting Visual Context for Unsupervised Event Segmentation in Continuous Photo-streams
Segmenting video content into events provides semantic structures for indexing, retrieval, and summarization. Since motion cues are not available in continuous photo-streams, and annotations in lifelogging are scarce and costly, the frames are usually clustered into events by comparing the visual features between them in an unsupervised way. However, such methodologies are ineffective to deal with heterogeneous events, e.g. taking a walk, and temporary changes in the sight direction, e.g. at a meeting.
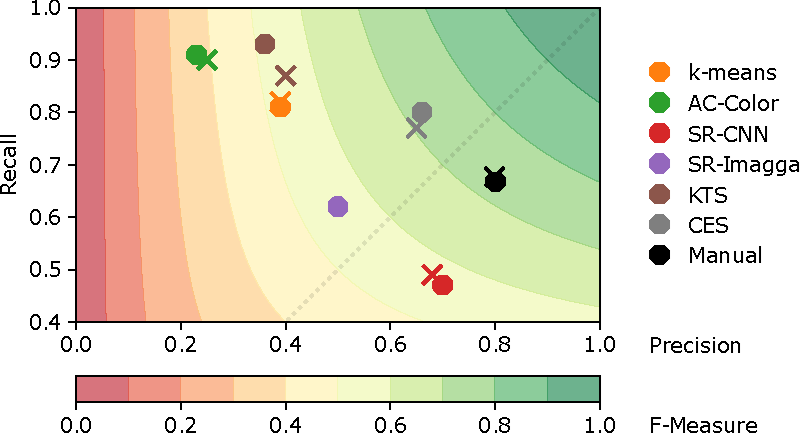
To address these limitations, we propose Contextual Event Segmentation (CES), a novel segmentation paradigm that uses an LSTM-based generative network to model the photo-stream sequences, predict their visual context, and track their evolution. CES decides whether a frame is an event boundary by comparing the visual context generated from the frames in the past, to the visual context predicted from the future. We implemented CES on a new and massive lifelogging dataset consisting of more than 1.5 million images spanning over 1,723 days. Experiments on the popular EDUB-Seg dataset show that our model outperforms the state-of-the-art by over 16% in f-measure. Furthermore, CES’ performance is only 3 points below that of human annotators.

CES in action for one example lifelog from EDUB-Seg:
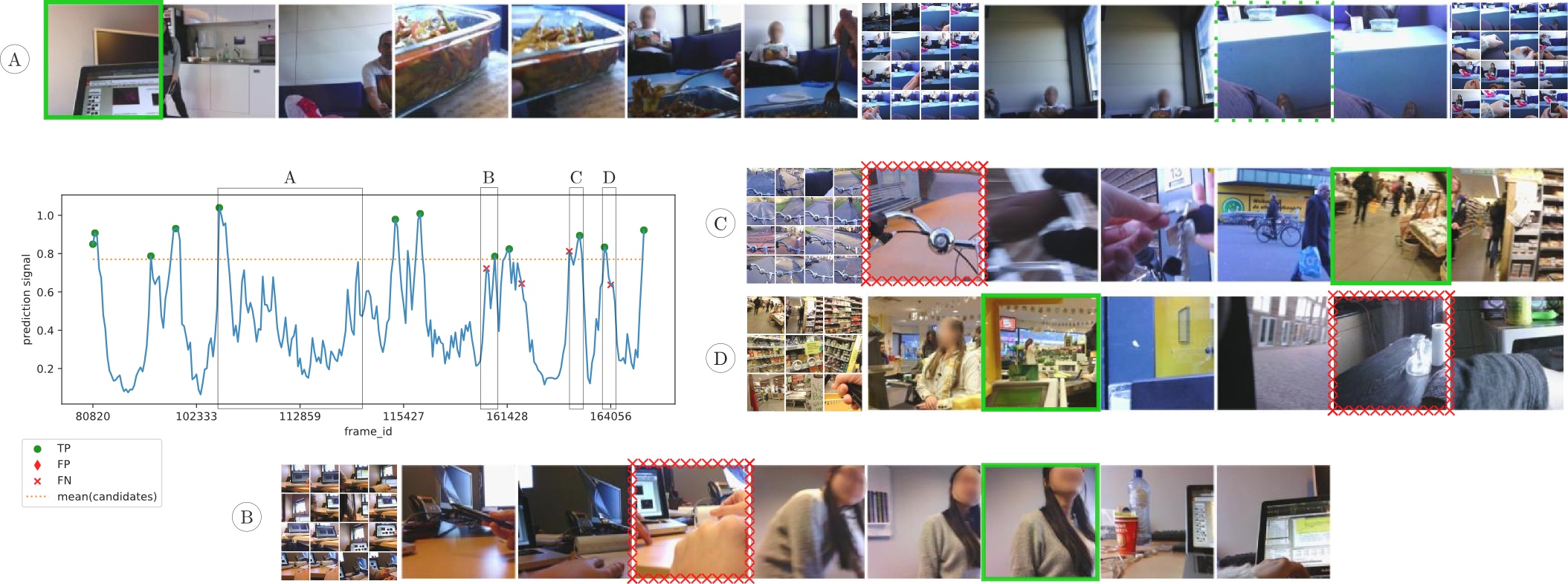
In this example, those frames which are false positives or false negatives in the baselines are highlighted. Unlike the baselines, CES is able to ignore occasional occlusions as long as the different points of view span less frames than CES’ memory span (A). It is also capable of detecting boundaries that separate heterogeneous events such as riding a bike on the street and shopping at the supermarket (C, D). Most of the boundaries not detected by CES correspond to events that take place within the same physical space (B) and short transitions (C, D), e.g. parking the bike.
Method Overview

CES consists of two modules:
- the Visual Context Predictor (VCP), an LSTM (1) network that predicts the visual context of the upcoming frame, either in the past or in the future depending on the sequence ordering. An auto-encoder architecture (2) is used to train VCP with the objective of reaching minimum prediction mse.
- the event boundary detector (3), that compares the visual context at each time-step given the frame sequence from the past, with the visual context given the sequence in the future.
Experimental Results
Over a series of experiments, we observa that while most state-of-the-art methods fall within the mid-range performance in terms of f-measure, CES stands out of the baselines, improving their performance by over 15%, and positioning itself on the upper range of the absolute spectrum. The performance of CES is even competitive with that of the manual annotations.