Active Video Summarization:
Customized Summaries via On-line Interaction with the User.
To facilitate the browsing of long videos, automatic video
summarization provides an excerpt that represents its content.
In the case of egocentric and consumer videos, due
to their personal nature, adapting the summary to specific
user’s preferences is desirable. Current approaches to customizable
video summarization obtain the user’s preferences
prior to the summarization process. As a result, the user needs
to manually modify the summary to further meet the preferences.
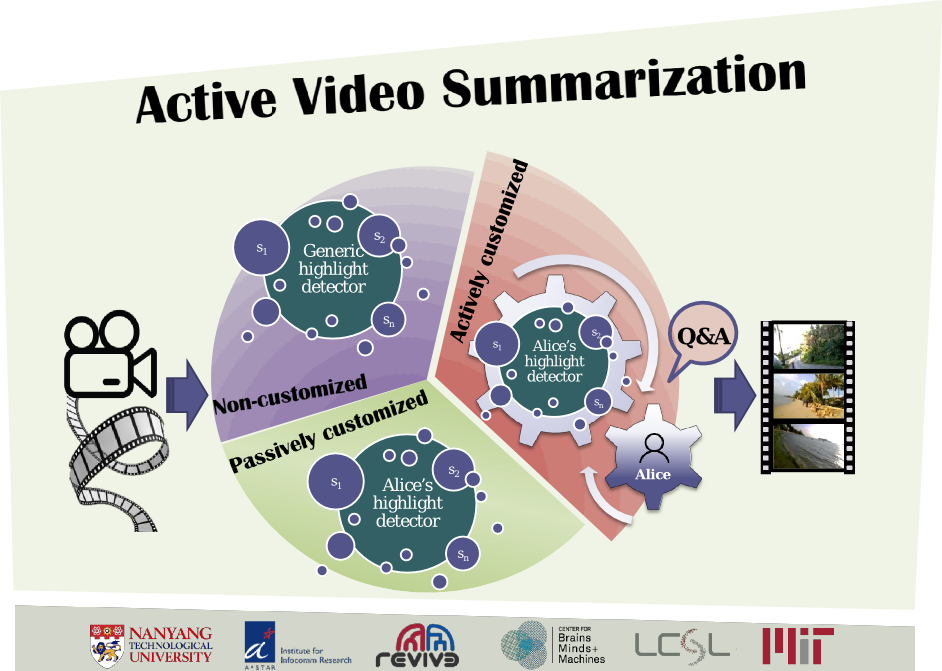
In this paper, we introduce Active Video Summarization
(AVS), an interactive approach to gather the user’s
preferences while creating the summary. AVS asks questions
about the summary to update it on-line until the user is satisfied.
To minimize the interaction, the best segment to inquire
next is inferred from the previous feedback. We evaluate
AVS in the commonly used UTEgo dataset. We also
introduce a new dataset for customized video summarization
(CSumm) recorded with a Google Glass.
The results
show that AVS achieves an excellent compromise between
usability and quality. In 41% of the videos, AVS is considered
the best over all tested baselines, including summaries manually
generated. Also, when looking for specific events in the
video, AVS provides an average level of satisfaction higher
than those of all other baselines after only six questions to the
user.
The aim of AVS is to provide a customized summary with as
little effort as possible from the user side. The system first
asks for the user’s initial preferences, selected from a set
of items, i.e. the most frequent items in the original video.
Then, the user’s preferences are further refined through a
question-asking inference.
AVS asks the user specific questions about segments of
the video. It shows one selected segment, and asks the following
two binary questions:
- Would you want this segment
to be in the final summary?
- Would you want to
include similar segments?
Note that the original video is not shown to the user, as the
segments shown during the interaction, and the subsequently generated summaries, provide an accurate
idea of the video content in much less time.
Thus, AVS can be divided into two inference problems:
- infer the customized summary, and
- infer the next
segment to show.
We use a probabilistic approach
based on active inference in Conditional Random Fields
(CRFs) to infer the most likely summary,
and to estimate the next question to ask.
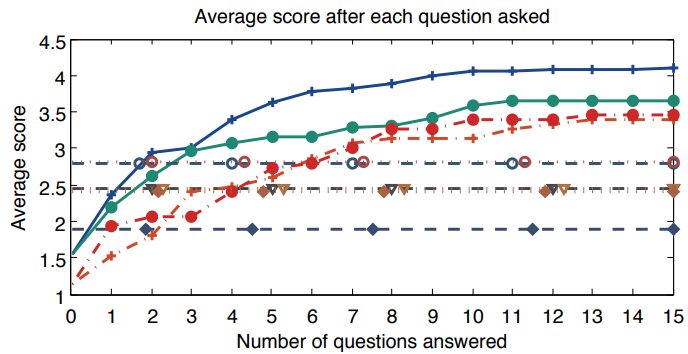
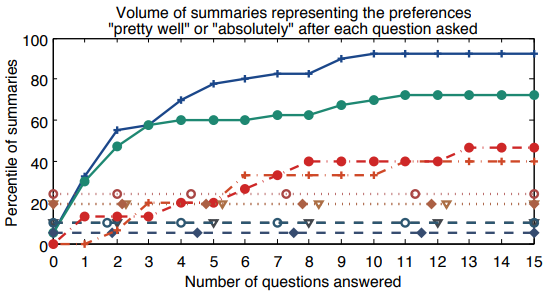
Experimental Results
We analyze two scenarios in which AVS can be used in practice.
In the first scenario, the user has to summarize a video
never seen before. The user has no knowledge of the video
essence, and thus does not know yet what are the relevant
parts. AVS allows the user to discover his or her own preferences
while exploring the video content. Generating summaries in this scenario with AVS results
4 times faster than doing it manually.
In the second scenario, the user already knows the content
of the video (e.g. the user was the camera wearer), and
already knows his or her preferences. However, due to the
length of the original video, looking for such preferences in
the video is very time consuming. AVS allows for the user
to browse the video and find such events easier and faster.
To test AVS in this scenario, we gave the users a set of element to be found in the video.
We score the summaries according to how many events appear on it.
The results using the different baselines are the following: